Случилась тут такая фигня. Выделил я под виртуальную машину всего ничего - 8Гб. И жил там себе и радовался. А тут на тебе, работы как привалило и внезапно я ощутил боль от такого вот опрометчивого шага. А сам VirtualBox как-то не разрешает динамически взять так и хопа сделать виртуальный хард больше. Оно и понятно, гостевая операционка с ума сойдет от таких поворотов. И решил я создать ещё один виртуальный хард и присоединить его к своей виртуалке и всё самое толстое (своё барахло по работе, базы мускульные, тонны дампов софта и тп лабудень) перенести на этот новый хард. Ну вот отрезал я значит ещё 20Гб, перезапустил виртуалку ии.. Само собой ничего автоматом не подхватилось. Поскольку в настройке линукса я новичек практически, пошел я гуглить. Ну и нагуглил ссылочку раз (как прицепить новый хард) и ссылочку два (как его отформатировать). В общем очень интересно было покрутить мозгами в ночи и постучать в бубен чуток :) Вот что примерно пришлось проделать.
sudo fdisk -l /* хм.. диск есть в системе. это круто. но на нем непонятная файловая система и нету разделов. кстати разделы можно посмотреть командой ls /dev/disk/by-uuid например, там ещё можно по-другому поглядеть, смотрим ls /dev/disk/ ну чо дальше.. ну думаю форматну-ка я его. */ sudo mkfs.ext3 /dev/sdb sudo fdisk -l /* о, круто, больше на разметку диска не ругается теперь значит можно раздел создать (я наоборот сделал, надо было сначала раздел а потом форматировать, но и так тоже работает как ни странно) */ sudo fdisk /dev/sdb /* тут мастер меня поспрашивал чего я хочу, я захотел один первичный раздел со всеми дефолтными настройками */ sudo fdisk -l /* ну что, всё круто. никаких матюгов уже не видно. премонтировать чтоли надо теперь. */ cd /home sudo mkdir disk2 sudo mount /dev/sdb /home/diks2 cd /home/disk2 ls -la /* ура. примонтировано. lost+found папку видно. отлично. ну теперь вроде как всё просто. надо дать себе на эту папку прав, бросить линк на неё в хомяк для удобства (моего) и радостно переложить туда всё своё барахло. */ sudo mkdir web sudo chown ijin:ijin web cd ~ ln -s /home/disk2/web /* во. теперь /home/ijin/web -> /home/disk2/web всё. в конфигах апача поправил пути ну и всё. смотрю свободное место.. */ df -h /* и вижу что на первом диске весь этот секс освободил мне каких-то 800 МБ всего-то. так, думаю.. вот хренота. ещё пару жирненьких дампов в БД волью и привет. Надож как-то всё жирное унести .. минут 5 пытаюсь руками найти где лежат мускульные базы. ищу вручную найти не могу. вспоминаю про волшебную утилитку du. делаю значит.. */ cd / sudo du -h | grep mysql /* rem: sudo - чтобы ходить по всем-всем папкам, даже тем в которые у моего юзера нет доступа. и вижу ацкий поток строк. смотрю на строчки которые du отдает (хорошо уже глазки привыкли на всё подряд регулярные выражения примерять :) и вижу, что указанный размер в Гб можно легко выловить из этого потока шлака. у grep есть клёви ключик -r, который позволяет не тупо искать подстроку а искать строчку совпадающую с регулярным выражением. */ cd / sudo du -h | grep -r .*G.*mysql.* /* и вот они искомые обожравшиеся папки :) везение конечно чистой воды, наверняка есть способ проще узнать где лежат мускульные базы, или просто нефигово бы знать где они лежат.. но в общем вот так вот при помощи кувалды и какой-то матери :) пришли к нужному результату. как говорил товарищ Христос "ищите и обрящите" (с) =) */Ну дальше понятно, упер базы на другой диск. Вот такая вот карусель. Чем больше калупаюсь с линуксом тем больше он мне нравится. Там всё можно сделать миллионом разных способов. Границ практически нет. Космические знания не нужны - под рукой всегда есть man и гугл. Только желание по сути. Я ещё хотел как-то написать про настройку сети в VirtualBox при том что ноут у меня ходит в сеть не по проводу, а через вайфай роутер, и одним коннектом на инет не обойтись, так как при таком раскледе на виртуалку не зайти, и надо было ещё один сетевой интерфейс поднимать, но это.. как говорится, совсем другая история :) Удачи вам. In byte we trust ;)/* теперь наверное осталось закрепить успех в /etc/fstab для чего исполняем */ sudo mcedit /etc/fstab /* и в нем по аналогии с "UUID=бебебе / бебебе" (это подключение основного раздела первого диска по UUID я так понимаю) прописываем /dev/sdb /home/disk2 бебебе как в оригинальной строке хвост про ext3 и ещё какая-то "лабуда" это надо затем чтобы после каждой перезагрузки не приходилось обламываться от того что второй диск не подключен и при загрузке демоны которые с него почитать хотят страшными словами ругаются, кроме того.. ну к нему тупо не будет доступа пока не скажешь */ sudo mount /dev/sdb /home/disk2 /* в общем вот так должно быть примерно в фстабе */
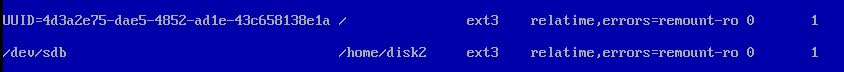
P.P.S.: да, при переносе баз в другое место я огреб уже известную с 8.04 проблему с apparmor. Фиксится это просто:
sudo mcedit /etc/apparmor.d/usr.sbin.mysqld # меняем путь в строках # /var/lib/mysql/ r, # /var/lib/mysql/** rwk, # на свой # /home/disk2/mysql_db/ r, # /home/disk2/mysql_db/** rwk, sudo /etc/init.d/apparmor restart sudo /etc/init.d/mysql restart # взлёт. 5 минут полет нормальный. =) # права на папки 755, на файлы 660 # пользователь и группа на всё mysql:mysql
Линукс это здорово. Суть проблемы такая. Вот прямо с листа как есть, думаю есть много похожих проблем водится у народа. Есть папка с компилированными шаблонами смарти. Если грохнуть все компиленные шаблоны в ерорлоги нападает ошибок на тему не могу найти бла-бла-бла такой шаблон. Это потому, что боевая площадка под нагрузкой, и удаление попадает между вызовом страницы с проверкой оригинала шаблона + проверкой наличия компиленной версии и обращению к скомпилированному шаблону. То есть обратились, оригинал проверили ок и скомпиленный шаблон есть, а тут мы такие со своим удалением. Ну это ерунда конечно. Пользователь просто увидит недозагруженную страницу без ошибок, клацнет по ф5 и расслабится, поскольку на этот раз штатный механизм отработает правильно и шаблоны перекомпилируются.
Так вот, чтобы не грохать всё и не портить людям жизнь ("не ломайте мой кайф!!!" ©) бывает нужно грохнуть один единственный шаблон с уникальным именем. Скомпилированные шаблоны имеют не сильно красивые имена вроде%что-то_адское%оригинальное_имя_шаблонаВ mc искать неудобно, то есть просто нереально потому что он совсем некрасиво сокращает имена. Как быть. Да всё просто.
# убедимся что мы в целевой папке pwd # ага, всё ок, теперь ищем шаблон ls | grep ololo # тут нам вернут имя шаблона, можно просто набить unlink # выделить полученное имя и копирнуть его в командную строку # но когда тебе надо это исполнить раз несколько подряд.. # мышь утомляет. Как автоматом сунуть анлинку результат? Легко! unlink `ls | grep ololo`rem: unlink не возьмет больше одной строчки с параметрами. Поэтому если греп вернет больше одного файла всё поломается. Для страховочки можно использовать ключик для грепа который ограничевает кол-во результатов, выглядит это так grep -m 1 ololo, тут греп вернет строго не больше одного файла. Но это уже по сути к делу не относится. Этот тип для разумных, мыслящих гуманоидов тусующих по консолям.
Дальше конечно возник вопрос как быть если хочется грохнуть все файлы по маске а не только первый найденный. Выручили старшие товарищи, получилось сложнее и в то же время интереснее. Итого:
ls -1 | grep ololo | while read; do unlink "$REPLY"; doneЧтобы понять что происходит вместо unlink можно вставить простое echo.
Линукс придумали потрясающие люди и им надо поставить памятник. Всем. Всё просто:
# Тут ещё приделана выборка для именно 302-х запросов
tail -f /var/log/lighttpd.access.log | grep ' 302 '
# Прервать сей поток можно магическим сочетанием контрол + Ц. Собственно и всё.
# P.S.: -f, --follow[={name|descriptor}] output appended data as the file grows; -f, --follow, and --follow=descriptor are equivalent

localedef -c -i ru_RU -f CP1251 ru_RU.CP1251И для проверки исполняем:
locale -a | grep ruДолжны увидеть нашу сгенеренную. Но для работы этой локали мне например пришлось вирт машину перезагрузить :(
Мне это понадобилось потому что моя девзона работает внутри виртуальной машины, в которой время регулярно теряется и переставляется. Хотя бы просто потому, что виртуалка выключается за ненадобностью в нерабочее время. В общем синхронизироваться совсем просто на самом деле:
# Проверяем текущую таймзону more /etc/timezone # Если надо конфигурируем правильную? ту которая нам нужна sudo dpkg-reconfigure tzdata # Ставим собственно сам модуль sudo aptitude install ntpdate # Обновляем локальное время с удаленного ntp-сервера (ntp-сервера можно поглядеть в Gooogle) sudo ntpdate 0.ru.pool.ntp.org